Background
Throughout 2022, users of .legal’s products and services have experienced an exponential increase in functionality and modules. At the beginning of 2022, we relaunched our entire Privacy platform. With the relaunch, we introduced several user-friendly features making it easier for our users to document and manage their organisation’s personal data compliance. In addition, new features added to the platform and presented in 2022 include modules to risk assessment, an annual wheel and lists. Together, these initiatives result in better functionality and user experience for the users of .legal.

In the article below, our Head of Development, Troels Richter, has put the journey of .legal’s developing team down in writing. The article emphasises a story about how we moved from introducing four releases a year to 40 releases a year. Furthermore, it highlights the points of why increasing the number of releases is important, the obstacles associated with the releases and how we have addressed the obstacles along the way.
Part 1: From Quarterly to Monthly Releases
Introduction
If you have been a part of a software development start-up or a new greenfield project, you probably know the great feeling of the early days when you were in control and could deliver at a high pace. But at some point, the speed often stagnates, and it becomes increasingly harder to get each release out of the door. While your codebase grows and complexity increases bugs start to emerge, daily operation & customer support start to take up more time, and QA becomes harder while the demand to still be able to deliver at a high pace remains.
At .legal, we have been on the same journey. We spent the first couple of years building a product suite for our customers without paying too much attention to our long-term velocity. Slowly the cadence decreased to a point where we needed to face what could be done to regain the speed of the early days.
If you are sitting right now and wondering why you can’t deliver at the speed, you were used to this blogpost is for you. You are not alone and hopefully, sharing our story can inspire you to do something about it.
From early days speed to 3 weeks regression testing
Back in 2015, a small team of developers together with a product visionary started the journey of Pactius. All effort was put into building a new contract management system, from the ground up, which meant features, features, and even more features. At some point as GDPR became a hot topic a significant new section called "Privacy" was introduced into the Contract Management System due to synergies between managing a company’s contracts and GDPR in the same system.
When .legal was established in late 2019 Pactius was already a large system. Until then there had been little time to think about developer principles, the underlying tech stack, architecture scalability, delivery pipelines, auto-testing etc. But as time went by and the system codebase grew the consequences started to emerge. The lead time was increasing, and more and more bugs found their way to the surface adding more and more manual regression tests to the release process. It was hard to fix problems at the root due to a large codebase with little attention to reusability (DRY Principle) and testability. It left the developers with headaches because it was hard to see a way out other than adding to the already large amount of manual regression tests that all needed to pass before a new feature saw the daylight.
It came to the point where it took at least 3 weeks to stabilise a new feature because we were going through +250 manual regression tests before every single release. Releases should be announced to the customers in advance, and we only released them on a Friday afternoon because then we had the weekend to fix possible issues.
A negative side effect of the long stabilisation period was that some of the developers started to work on the next release because it was hard to occupy all developers with stabilisation. So parallel development tracks started to emerge and because the stabilisation track took up our testing environment the future development track was held back - again increasing the overall lead time and QA feedback loops.
It was clear that something needed to change, but it was also clear that this was not going to be a quick fix but more a transformation over time involving initiatives at many levels.
Continuous Delivery as the underlying belief system
Going forward we needed to build a common ground from where initiatives could emerge. Something more fundamental than increasing our speed and ability to release. We needed a new belief system that could act as the foundation for our long-term strategy.
On the surface "Continuous Delivery" sounds like something you want to pursue only to gain speed. But underneath the title, there are more profound principles that are heavily inspired and go hand-in-hand with Lean & Kanban.
- Build quality in
- Work in small batches
- Computers perform repetitive tasks, people solve problems
- Relentlessly pursue continuous improvement
- Everyone is responsible
[Source: https://www.continuousdelivery.com/principles]
I think these principles are strong because I don't think you can achieve continuous delivery if you do not live by these principles. And again, I think these principles foster a culture that brings meaning to a developer’s work culture.
If you "build quality in" you care about quality, you care about craftsmanship which makes most people feel proud.
If you "work in small batches" you need to work together as a team. Care for each other and help each other to follow through. It lowers multi-tasking and sharpens the team’s focus which again has a positive impact on quality.
If you make "computers perform repetitive tasks" then the engineers’ job is to build automation of everything that can be automated.
If you "continuously try to improve" you also accept and respect where you are now but have the motivation to always try to do a little better together.
If "everyone is responsible" then everyone feels ownership. If you feel ownership, then you care. You naturally want to do something positive for things you care for. Care is often appreciated by others.
At this point, the reality was that we needed initiatives for each and every principle. We had not built quality in, we worked in large batches, we did a lot of repetitive work, we did little to improve and only a few were responsible. This also made the principles valuable as a long-term belief system to strive for.
Shared ambition to release on a monthly basis
Our first step towards releasing more often was to agree that releasing more often was a good idea and be concrete about what to aim for.
Before we started our ambition was to release every quarter and our mindset and process were centred around that ambition. If we are only doing 4 releases a year maybe it is OK to spend three weeks to stabilise each release? So why change it?
It can be hard to argue why you should release more often when the risk and overhead of each release are high. The first step for us was to convince the product owner of the positive impacts of releasing often and make him believe that we were able to increase the release cadence without compromising quality.
A myriad of principles leads up to continuous delivery. Both at a process level (like software Kanban, Lean, Scrum etc.) and at a technical level (like Continuous Integration, Monitoring, Unit-testing, SOLID etc.). If you haven't been spending much time on the thoughts behind continuous delivery, it can be a lot to comprehend.
Our product owners’ support where a critical first step because releasing often is (from my point of view) as much an approach and skillset from a product owners’ standpoint that needs to spread to the developers as the other way around.
After a while, we landed our first shared ambition to do what it took to release on a monthly basis.
Scoping releases in monthly chunks
If you are used to thinking of product development in quarterly releases it is a big change to start thinking about deliveries every month. It required a change in mindset for all of us starting with the product owner. Instead of striving for the perfect solution to start with it was a matter of always thinking in good compromises.
"How can we deliver a first barebone version that we think brings just enough features to test out the concept and still deliver some value to the end user?"
As an example, we wanted to develop a new dashboard solution. The initial ambitions for the solution were sketched out in visual mock-ups.
Dashboard with pages of six widgets
Deep dive into data by clicking on a widget 
Configurable dashboard with drag-and-drop support
Instead of aiming for the full-blown dashboard solution with all wanted widgets at once, we needed to ask ourselves questions on how to narrow it down to a minimum. How few widgets are we able to get away with and still call it a dashboard? Which ones did we think were the most important? Could we for with the ability to dive into data until later? Maybe instead just track how many of the users actually tapped on a widget?
It requires a completely different approach to start thinking in incremental deliveries instead of the perfect solution upfront. Instead of asking the developers for estimates on a fixed scope, it is more a matter of asking the developers "What are we able to cut away to be able to release this feature set in a month?". It puts the developers in a more creative but also challenging position because they have to come up with pragmatic solutions in collaboration with the product owner.
A positive side effect was that this approach brought us into a mode of being more curious about user feedback. We now wanted validation of the initial version before we moved on with the next incremental steps towards the long-term solution. Why spend a lot of time, adding complexity if very few users actually tapped on the widgets of the dashboard?
Fighting parallel-release tracks
During the regression test period, it was hard to occupy everyone with QA resulting in parallel development tracks which again resulted in daily bottlenecks because everything needed to go through the same test environment. Again, this often meant that there was no internal QA feedback loop on future development until the current release was stabilised and ready to deploy.
It became a vicious spiral increasing our work in progress which again harmed our lead time, focus, collaboration, and overall speed.
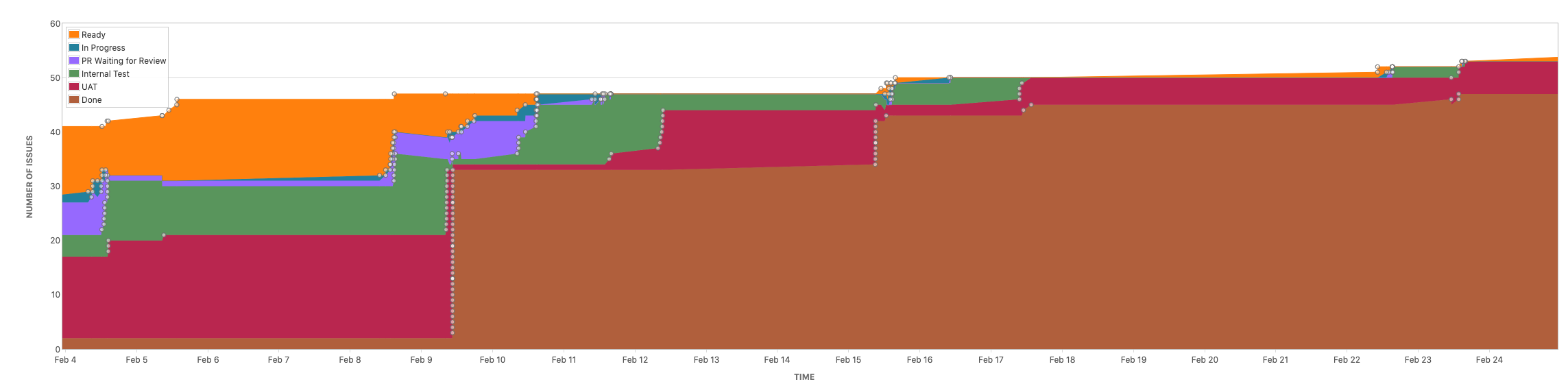
The cumulative flow diagram above is from our release 2021.2 from the 4/2 where 2021.1 was released to when 2021.2 was released. As you can see much was already in progress at the date when the previous release was deployed. Most are in the internal test and user acceptance test stage and from 9/2 a long period of stabilisation.
Lowering the amount of work that was put into every release would normally lower the regression test period, but because we had a monolithic architecture the practice was to run through all tests to be sure we haven't broken anything.
Therefore, the first initiative was to lower the number of manual regression tests. Instead of going through all +250 regression tests for each release, we did some initial work to get an overview of the actual code changes for the given release and map the actual changes to the regression tests. If we could document that we haven't touched a certain part of the system, why do the regression tests? This lowered the manual regression test period dramatically which again lowered the need for parallel development tracks.
Increase code quality through pull requests
The long-term plan for lowering the number of bugs was to improve code quality. The first initiative we agreed upon was to start reviewing each other’s code through pull requests. For some of us, it was a new practice, so we made it explicit what to look for when the reviewer went through a pull request.
Here is a subset of our internal pull-request guide:
- Have unit tests been added/expanded/changed?
- Check the naming of public types, then classes, interfaces, etc - as well as the methods and properties that are public. Are they spelt correctly (helps with searching the code) and do the names make sense? If there are abbreviations, is it common knowledge what it means, rather a slightly longer name?
- Is the naming understandable and uses consistent terms from the domain?
- Ensure that the logic is obvious
- Ensure there is no unused code.
- Ensure that we live up to our own "boy-scout rules". For example, is there duplicate code that should be pulled out in a variable or method
To this day we still do pull requests on everything we do and have revisited what to look for a couple of times.
Introduction of Retrospectives
To have a forum where we could talk about challenges and follow up on improvement initiatives, we introduced a monthly retrospective. It was usually as a result of a retrospective that a new experiment would arise and afterwards be tried out in the real world. When I think back, many of the initiatives described in this blogpost were a result of something initiated at a retrospective. In some periods held on demand and in others, when we were experiencing a lot of change, back to a steady cadence of a monthly basis.
Where did it leave us?
With the few initiatives described in this blogpost we slowly moved towards monthly releases. Most importantly I think we started to believe in and strive for Continuous Delivery. Over time we proved to ourselves that we were able to deliver in smaller increments while maintaining or maybe even improving the overall quality.
But we didn't want to stop there. We knew that we had some fundamental technical challenges because our underlying platform was outdated. We had a little degree of code reusability: we had no automatic tests and our codebase grew meanwhile the ambitions from a business perspective had never been higher.
So how could we move beyond the monthly release barrier and lower the overhead to a degree where we could deliver whenever we wanted to?
If you are still there, stay tuned until part two of the blogpost ...

.png?width=352&name=Feature%20image%20contract%20renewal%20(1).png)
.png?width=352&name=December%20release%20(1).png)




.jpeg)
.jpg)
.jpg)


.jpg)

-1.png)



.jpeg)





.jpg)











